Testing for Normality
Before jumping into testing, make sure you understand that the size of your sample really matters if you’re trying to decide if parametric testing is appropriate or not. More info about the impact of the size of the sample can be found in why we test for normality of data.
For actually testing, there are four main tests seen in the biomedical literature most commonly, and a fifth (D’Agostino) that occasionally crops up:
- Shapiro-Wilk Test – The Shapiro-Wilk Test is pretty much better than any of the other options without any real drawbacks [1]Razali, Nornadiah; Wah, Yap Bee (2011). “Power comparisons of Shapiro–Wilk, Kolmogorov–Smirnov, Lilliefors and Anderson–Darling tests”. Journal of Statistical Modeling and Analytics. 2 (1): 21–33. The one exception to this rule would be when you have many identical duplicate values in your sample, something that might occur if the precision of your measurements are low. For example, if you record weights of a sample of patients in only 10-kg increments (40kg, 50kg, 60kg, etc), instead of as more precise measurements like “54” or even “54.3”, Shapiro-Wilk won’t work as well. If you do have many duplicates and you think your distribution is still Normal use D’Agostino (or if your stats package can’t run that then use Anderson-Darling or CvM). Otherwise, or if you aren’t sure what to use, just use Shapiro-Wilk!
- D’Agostino Ominbus K2 Test – D’Agostino detects differences from normality in the skewness and kurtosis of the distribution. It’s seen less commonly than Shapiro-Wilk. If you are aiming for high statistical rigor and you know that your distribution has many duplicated values, note this in your methodology and use D’Agostino. Otherwise us Shapiro-Wilk.
- Anderson-Darling – Why are you still reading? Use Shapiro-Wilk. Anderson Darling is better than the other tests below for normality testing but not as good as Shapiro-Wilk.
- Cramer von-Mises – C’mon. You aren’t going to use this test. It has a silly name. And Shapiro-Wilk is still better.
- Kolmogorov-Smirnov – Despite being probably the most commonly reported normality test in the medical literature and sounding a lot like a tasty drink that might come out from the bar on fire, KS will have high sensitivity to extreme values, has low overall power, and should probably not ever be used given the other tests available. Even with Lilliefors correction it’s still not as good as Shapiro-Wilk [2]Stephens, M. A. (1974). “EDF Statistics for Goodness of Fit and Some Comparisons”. Journal of the American Statistical Association. American Statistical Association. 69 (347): 730–737. doi:10.2307/2286009. JSTOR 2286009. Seeing the trend here?
- There are other more esoteric numerical tests of normality, but they’re esoteric for a reason.
For reporting normality results, you need report only the p-value for the test result. p > 0.05 suggests an approximately normal distribution, with higher values being closer to normal. p < 0.05 suggests significantly different from normal at the 95% level, with lower values being more deviant. See Understanding Testing for Normality for cautions and interpretations of these tests, though!
There are graphical methods for testing for normality, but these generally aren’t used in manuscripts as they are more subjective in interpretation.
Example of Normality Testing
Let’s assume we have a study looking at the impact of some intervention on hospital length of stay, and we want to know if our length of stay data is normally distributed or not so we know whether to use a t-test or a Mann-Whitney U test to compare our groups. We have 35 data points in each group, so it’s not clear if we can safely use parametric tests or not (see understanding testing for normality to understand why the sample size matters). We’ll use real length of stay data from a clinical study looking at inpatients for major surgical procedures. The data is admit to discharge length in days expressed as an integer. Ideally, the data would have partial days stored as decimals, but with clinical data we don’t always get a choice of the resolution of our data.
As a comparison, we’ll also take 35 random data points from a normal distribution with the same mean value and standard deviation as the length of stay data. If you want to play along at home with your preferred statistical software, the samples we’re using are:
LOS data: 20,6,20,18,12,9,16,24,15,11,8,11,16,20,21,5,37,5,21,17,10,13,3,4,10,12,11,6,14,17,5,20,20,11,15,9
Normal sample: 7,11,9,17,14,7,26,23,9,5,8,7,29,3,21,5,12,10,16,19,15,16,16,17,15,14,15,18,12,21,7,5,22,19,11,13
The mean/SD of the LOS data is 13.7 ± 6.9. The mean/SD of the normal sample is 13.7 ± 6.3. Just looking at the mean and SD, the samples look pretty similar, and obviously mean/SD is not useful to assessing normality. Histograms of the two distributions show they actually look quite different (these histograms show larger samples of 200 measurements to give a better impression of the full shapes):
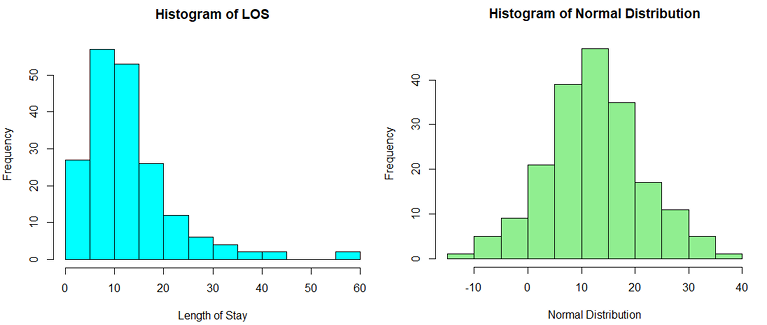
Now, right off the bat it’s pretty obvious that the LOS distribution is not symmetric – it’s right skewed, and from that alone we can tell it’s not normal. Another clue is that the normal distribution extends infinitely in both directions (on the histogram it goes below zero); LOS data cannot be less than zero, so it can’t be normal. Nevertheless, we’ll run through the testing to demonstrate what we can see here.
Running the Shapiro-Wilk test on the normal sample gives us a p-value of 0.56. This is >0.05, so the test is telling us the sample is not significantly different from the normal distribution. The Shapiro-Wilk test on the LOS data gives us a value of 0.028. This is <0.05, so it’s telling us this distribution is statistically different from normal. Note again that this information alone does not tell us whether using parametric tests is appropriate or not; it merely provides us more information to use in this decision. Also note that despite the duplicated values in both data sets, Shapiro-Wilk still gives the expected results; in general unless your data set is highly repetitive it should perform adequately.
If you have any doubt, run the Shapiro-Wilk test on your data. If the p-value is < 0.05, use non-parametric tests to play it safe.
Graphical Tests for Normality: PP & QQ
There are also graphical methods for testing of normality and other distributions. For manuscript reporting just use Shapiro Wilk. That’s all you need to do. Tests like Shapiro Wilk will tell you that your distribution isn’t normal and give you some estimation (via the p-value) of how non-normal it is. It doesn’t show you how it deviates from normal, though, whereas graphical tests will give you a better idea.
Histograms of the samples (like those above) are one very straightforward way to assess normality.
Probability plots (commonly known as PP and QQ plots) are used to visually compare an observed distribution to a reference distribution (usually the normal distribution, but any distribution could be tested for). They are the graphical equivalent to the tests above, but rather than giving you a numerical estimate of the non-normality, these graphical methods will show you in what way your distribution is different from the reference distribution. They can show you if the right and left tails are longer are longer or shorter than the reference distribution, for example.
The key difference in PP and QQ graphs is in how the graph values end up clustered on the resulting graph. A PP graph will typically exaggerate the center of the distribution, whereas a QQ graph will typically exaggerate the tails of the distribution. Because we are usually more interested in the tails, QQ graphs are more common.
In either case, PP or QQ, if the distributions match the graph will be a straight diagonal line. Example QQ plots are shown below.

References
| 1. | ↑ | Razali, Nornadiah; Wah, Yap Bee (2011). “Power comparisons of Shapiro–Wilk, Kolmogorov–Smirnov, Lilliefors and Anderson–Darling tests”. Journal of Statistical Modeling and Analytics. 2 (1): 21–33 |
| 2. | ↑ | Stephens, M. A. (1974). “EDF Statistics for Goodness of Fit and Some Comparisons”. Journal of the American Statistical Association. American Statistical Association. 69 (347): 730–737. doi:10.2307/2286009. JSTOR 2286009 |